
In the first and second parts of this series, we introduced you to the basics of API development with the TNDP.
We’re now going to explore two further capabilities.
OIM JSON
One of the problems which XBRL has as a standard is the letter X. The original specification is very closely tied to the XML syntax used. Recently, the OIM (Open Information Model) Working Group has been capturing the semantics of XBRL in a way which will allow them to be separated from the original XML syntax, and expressed in a standard manner in various formats. The first such format under development is JSON, since it is commonly used in modern web applications and APIs.
CoreFiling is heavily involved in the working group, and although the OIM and xBRL-JSON specifications are not finalized at the time of writing, our platform offers a beta implementation which allows existing XBRL filings to be converted to JSON.
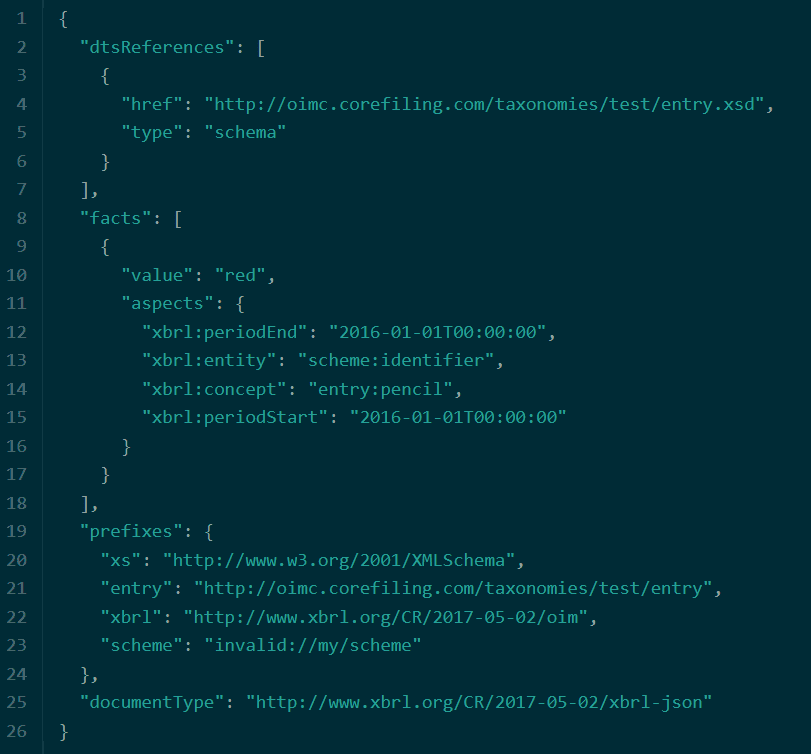
You can try this out with code such as the following (this assumes you have already loaded a filing onto the platform; see the previous post for details on that). You can also find all the code samples from this blog series on GitHub.
#!/usr/bin/env python3
SERVICE_CLIENT_NAME = "(insert yours)"
SERVICE_CLIENT_SECRET = "(insert yours)"
BASE_URL = 'https://api.labs.corefiling.com/'
import re
import json
import requests
import time
from os.path import expanduser
from requests.auth import HTTPBasicAuth
def main():
# Authenticate and obtain access token. More usually an OAuth2 client library would be used
at_response = json.loads(requests.post('https://login.corefiling.com/auth/realms/platform/protocol/openid-connect/token',
data={'grant_type':'client_credentials'},
auth=HTTPBasicAuth(SERVICE_CLIENT_NAME, SERVICE_CLIENT_SECRET)).text)
access_token = at_response['access_token']
auth_header = {'Authorization': 'Bearer ' + access_token}
filing_version_id = input("Enter filing version ID to obtain as OIM JSON: ")
# Get the output document ID for an OIM rendering and then download the JSON
outputs_req = requests.get(BASE_URL + 'document-service/v1/filing-versions/' + filing_version_id, headers=auth_header)
outputs_req.raise_for_status()
documents_by_category = {}
for document in json.loads(outputs_req.text)['documents']:
documents_by_category[document["category"]] = document["id"]
json_req = requests.get(BASE_URL + 'document-service/v1/documents/%s/content' %documents_by_category['json-rendering'], headers=auth_header)
json_req.raise_for_status()
oim = json_req.json()
print(json.dumps(oim, indent=2))
if __name__=='__main__':
main()
Filing Statistics
XBRL filings can be enormous, and sometimes it’s hard to make sense of the information. If you’re looking for a quick summary of a filing, we offer a simple set of statistics about any filing which can be accessed as follows:
#!/usr/bin/env python3
SERVICE_CLIENT_NAME = "(insert yours)"
SERVICE_CLIENT_SECRET = "(insert yours)"
BASE_URL = 'https://api.labs.corefiling.com/'
import re
import json
import requests
import time
from os.path import expanduser
from requests.auth import HTTPBasicAuth
def main():
# Authenticate and obtain access token. More usually an OAuth2 client library would be used
at_response = json.loads(requests.post('https://login.corefiling.com/auth/realms/platform/protocol/openid-connect/token',
data={'grant_type':'client_credentials'},
auth=HTTPBasicAuth(SERVICE_CLIENT_NAME, SERVICE_CLIENT_SECRET)).text)
access_token = at_response['access_token']
auth_header = {'Authorization': 'Bearer ' + access_token}
filing_version_id = input("Enter filing version ID to obtain statistics for: ")
# Obtain and print the filing statistics
stats_req = requests.get(BASE_URL + 'filing-statistics-service/v1/filing-versions/%s/statistics/' % filing_version_id, headers=auth_header)
stats_req.raise_for_status()
print(json.dumps(stats_req.json(), indent=2))
if __name__=='__main__':
main()
This should produce output like this:
[
{
"label": "Number of facts",
"name": "fact-count",
"format": "integer",
"value": 92
},
{
"label": "Number of concepts",
"name": "concept-count",
"format": "integer",
"value": 61
},
...
Again, the code for this can be found on Github. You can request an API key and try the API by contacting us.
In the final instalment in this series, we will demonstrate opportunities for embedding results from the TNDP in your own applications and web pages.